Map
HashMap原理
Java 8 及以上版本的 HashMap 底层维护一个 Node<K,V>[] table 数组,索引通过 key.hashCode() & (table.length-1) 计算得到;当单个桶中元素过多(>8)时,链表会“树化”为红黑树以降低查找复杂度,否则以链表存储
-
当我们往HashMap中put元素时,利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
-
存储时,如果出现hash值相同的key,此时有两种情况。
a. 如果key相同,则覆盖原始值;
b. 如果key不同(出现冲突),则将当前的key-value放入链表或红黑树中
- 获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
HashMap的jdk1.7和jdk1.8有什么区别
-
JDK1.8之前采用的是拉链法。拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
-
jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8) 时并且数组长度达到64时,将链表转化为红黑树,以减少搜索时间。扩容 resize( ) 时,红黑树拆分成的树的结点数小于等于临界值6个,则退化成链表
红黑树是一种自平衡二叉搜索树,查找、插入、删除均为 O(log n),而链表最坏查找需遍历为 O(n)。当链表过长时,红黑树能显著降低查询延迟
当链表长度很小(如 <8)时,为什么使用链表优于树?
当桶内元素较少(默认阈值小于 8)时,链表的插入和遍历在节点数很少的情况下开销更低,不需要额外的旋转、染色等平衡操作
而将链表转换为红黑树需要创建 TreeNode、执行多次旋转与重染色,单次转换成本较高,只有当冲突严重、查询次数很多时才体现出 O(log n) 的优势
向HashMap添加元素过程
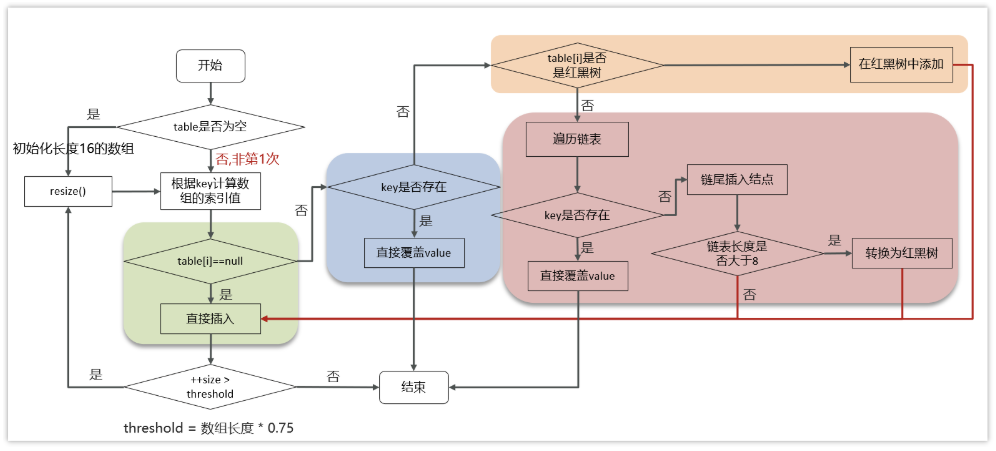
-
判断键值对数组table是否为空或为null,否则执行resize()进行扩容(初始化)
-
根据键值key计算hash值得到数组索引
-
判断table[i]==null,条件成立,直接新建节点添加
-
如果table[i]==null ,不成立
-
4.1 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value
-
4.2 判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对
-
4.3 遍历table[i],链表的尾部插入数据,然后判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操 作,遍历过程中若发现key已经存在直接覆盖value
-
插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold(数组长度*0.75),如果超过,进行扩容。
假如key是User对象,这个对象需要做什么特殊处理吗
必须重写
hashCode()和equals()方法
因为HashMap 中存取值,都是依据 key 的 hashCode 值,若未重写,默认使用内存地址计算哈希值,导致相同属性的对象因地址不同而存入不同位置。
equals() 用于在哈希冲突时比较键的等价性。若未重写,默认使用 == 比较内存地址,导致相同属性的对象被误判为不同键。
确保对象的不可变性
若 User 对象作为键后发生属性修改,会导致哈希值与存储位置不匹配,从而无法正确检索数据
链表转红黑树阈值
链表转红黑树阈值(8)的选择
泊松分布概率分析:在理想随机哈希码下,单个桶中出现8个元素的概率约为0.00000006(小于千万分之一),几乎不可能自然发生,因此把8作为触发阈值可以保证极端情况下的查找性能,同时避免在常规场景中无谓的树结构开销
空间与时间的折中:红黑树节点占用的空间大约为普通链表节点的两倍,将链表长度过短时就treeify会带来额外内存和旋转开销,不利于常规O(1)插入/查询的性能。因此仅在链表长度达到8时再treeify,能够以较小的空间成本换取极端情况下O(log n)的查找保证
红黑树降级回链表阈值(6)的选择
避免频繁转换,若将untreeify阈值同样设为8,当哈希冲突数在7至8之间波动时,桶会在链表和红黑树间频繁互相转换,导致不必要的旋转和内存分配/回收,进而影响性能。将回退阈值下调至6,可以扩大稳定区间,从而减少抖动
HashMap 是线程安全的吗?那线程安全的 Map 有哪些?
HashMap 是非线程安全的,因为它不是同步的,多个线程同时对 HashMap 进行操作可能会导致数据不一致的问题。
Java 提供了多种线程安全的 Map 实现,包括:
ConcurrentHashMap:它是线程安全的,采用分段锁机制,不同的段(Segment)可以被不同的线程同时访问,从而提高了并发性能。
Hashtable:它是线程安全的,但是性能相对较差,因为它在每个方法上都使用了同步锁。
Collections.synchronizedMap:它可以将非线程安全的 Map 转换为线程安全的 Map,但是性能相对较差,因为它在每个方法上都使用了同步锁。
在选择线程安全的 Map 时,需要根据实际情况进行选择。如果需要高并发性能,可以选择 ConcurrentHashMap;如果需要完全的线程安全,可以选择 Hashtable;如果需要将非线程安全的 Map 转换为线程安全的 Map,可以选择 Collections.synchronizedMap。
解决哈希冲突的常用方法
开放定址法
从发生冲突的那个单元起,按照一定的次序,从哈希表中找到一个空闲的单元。然后把发生冲突的元素存入到该单元的一种方法。开放定址法需要的表长度要大于等于所需要存放的元素。 在开放定址法中解决冲突的方法有:线行探查法、平方探查法、双散列函数探查法。 开放定址法的缺点在于删除元素的时候不能真的删除,否则会引起查找错误,只能做一个特殊标记。只到有下个元素插入才能真正删除该元素。
链地址法(拉链法)
链接地址法的思路是将哈希值相同的元素构成一个同义词的单链表,并将单链表的头指针存放在哈希表的第i个单元中,查找、插入和删除主要在同义词链表中进行。链表法适用于经常进行插入和删除的情况。
再哈希法
就是同时构造多个不同的哈希函数: Hi = RHi(key) i= 1,2,3 … k; 当H1 = RH1(key) 发生冲突时,再用H2 = RH2(key) 进行计算,直到冲突不再产生,这种方法不易产生聚集,但是增加了计算时间。
建立公共溢出区
将哈希表分为公共表和溢出表,当溢出发生时,将所有溢出数据统一放到溢出区。
哈希桶扩容
哈希算法有哪些
| 算法 | 输出长度(位) | 输出长度(字节) |
|---|---|---|
| MD5 | 128 bits | 16 bytes |
| SHA-1 | 160 bits | 20 bytes |
| RipeMD-160 | 160 bits | 20 bytes |
| SHA-256 | 256 bits | 32 bytes |
| SHA-512 | 512 bits | 64 bytes |